Progress Review Paper tentang Komputasi Parallel
Hari ini, kami ditugaskan untuk menyampaikan hasil review kami tentang salah satu paper terkait komputasi parallel, GPU dan komputasi grid. Untuk tugas ini, saya memilih paper berjudul “A Grid-based Virtual Reactor: Parallel Performance and adaptive load balancing” yang dapat ditemukan di sini. Selain latar belakang riset yang saya bawa, paper ini juga saya pilih karena permintaan Prof. Heru agar saya mereview paper terkait teknologi nuklir. Meski bukan mengambil kasus teknologi nuklir, paper yang saya pilih menggunakan aplikasi terkait simulasi e-science, lalu mempelajari aspek penyeimbangan beban komputasi.
Secara umum, paper ini membahas tentang deployment aplikasi simulasi e-science ke infrastruktur grid. Aplikasi yang awalnya dibangun untuk infrastruktur cluster yang homogen dengan kendali terpusat, harus diberikan perlakuan khusus agar berjalan efektif di lingkungan grid yang heterogen dengan kendali tersebar. Sedangkan contoh kasus komputasi yang digunakan adalah simulasi plasma kimia pada reaktor maya untuk pelepasan uap. Targetnya tentu saya mempertahankan efisiensi derajat parallelisme pada komponen komputasi yang dieksekusi secara parallel.
Langkah pertama adalah mempelajari apa yang dilakukan penulis dalam melakukan riset. Yang pertama, para penulis mempelajari karakteristik solver / modul komputasi parallel. Aplikasi simulasi reaktor maya terdiri dari beberapa modul yang saling berhubungan, baik secara loosely coupled maupun tighly coupled. Pada tahap ini, para penulis mengambil salah satu modul komputasi yang memodelkan pelepasan uap plasma kimia. Dengan pengetahuan mengenai karakterisktik modul komputasi tersebut, para penulis mengembangkan teknik sehingga eksekusi modul tersebut agat dapat dieksekusi secara efisien di lingkungan grid. Setelah teknik berhasil dibangun, para penulis sampai pada tahapan mengevaluasi efisiensi dari teknik yang dikembangkan. Untuk tujuan ini, para penulis melakukan pengujian di infrastuktur RDG (Russian-Dutch Grid).
Untuk modul komputasi yang dipilih tersebut, diketahui bahwa dibutuhkan simulasi aliran 3 dimensi pada reaksi kimia pelepasan plasma di ruang geometri yang rumit. Simulasi ini membutuhkan sumber daya komputasi yang tinggi. Dengan grid, kebutuhan tersebut secara maya dapat dipenuhi nyaris tanpa batas. Sayangnya, keunggulan tadi membutuhkan teknik adaptasi modul komputasi agar dapat dieksekusi secara efisien di lingkungan grid. Terkait efisiensi komputasi parallel, ada dua aspek yang harus diperhatikan. Kedua aspek tersebut adalah karakteristik aplikasi dan sumber daya komputasi. Aspek pertama terkait dengan banyaknya data yang ditransmisikan sepanjang proses komputasi. Sedangkan aspek kedua terkait prosesor, kapasitas memori, kondisi jaringan, tingkat keberagaman sumber daya serta dinamika penugasannya.
Secara umum, ada beberapa pendekatan yang dapat dilakukan terkait penyeimbangan beban.
- Pendekatan yang dilakukan tanpa modifikasi di level aplikasi, tetapi di level sistem/pustaka. Contoh dari pendekatan ini adalah teknologi MOSIX (Multicomputer Operating System for Unix) serta paper yang dapat diperoleh di alamat ini.
- Pendekatan yang dilakukan di sisi kode sumber aplikasi. Pendekatan ini dilakukan oleh paper yang dapat diperoleh di alamat ini dan ini.
- Pendekatan yang dilakukan di sisi aplikasi, bukan hanya menambahkan kode sumber untuk menyeimbangkan beban, tetapi memodifikasi kode sumber terkait algoritmanya. Pendekatan ini dilakukan oleh paper yang dapat diperoleh di alamat ini.
.
Dari berbagai pendekatan tersebut, para penulis mengemabil pendekatan yang mereka sebut application centric, di mana keputusan penyeimbangan beban diambil dari aplikasi itu sendiri. Sedangkan algoritma yang dikembangkan bersifat generik, sehingga dapat diterapkan di aplikasi apapun yang dieksekusi di mesin-mesin yang heterogen.
Selain itu, dalam optimasi beban global untuk sumber daya yang heterogen dan aplikasi adaptive mesh refinement, telah dilakukan penelitiannya pada alamat ini, ini, dan ini.
Akan tetapi, dalam penelitian tersebut, tidak dipertimbangkan keberagaman sumber daya koneksi jaringan dan estimasi sumber daya secara dinamis. Berbagai pendekatan yang telah dilakukan sebelum penulis memang belum saya review lebih dalam, yang jelas, apa yang dilakukan penulis paper ini cukup memberi gambaran tentang apa kontribusi yang mereka lakukan. Semoga di waktu lain dapat saya review berbagai pendekatan yang telah disebutkan tim penulis.
Selanjutnya, disampaikan bahwa distribusi beban yang optimal memiliki dua karakteristik. Keduanya adalah sebagai berikut.
- Setiap prosesor memiliki beban kerja yang sebanding dengan kapasitas komputasinya.
- Komunikasi antar prosesor minimal.
Akan tetapi, kedua karakter ini justru saling bertolak belakang. Untuk kondisi ekstrim, komunikasi yang minimal hanya dapat dicapai ketika tidak ada komunikasi antar prosesor yang konsekuensinya beban kerja pasti tidak seimbang. Karenanya, diperlukan optimasi keduanya.
Secara generik, biaya yang diperlukan dalam perhitungan secara parallel dapat diformulasikan sebagai berikut.
Dengan 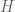
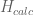



Jika dilihat lebih detil, biaya komputasi secara parallel dipengaruhi oleh parameter aplikasi, dinotasikan sebagai 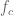
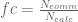
dengan 

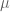



Nilai
Untuk memperkirakan nilai
Secara langsung. Hal ini dilakukan dengan memodifikasi kode sumber aplikasi. Akan tetapi, hal ini sangat sulit dilakukan dan penerapannya tidak generik.
Secara tidak langsung. Pendekatan ini dilakukan dengan melakukan benchmark secara terpisah berdasarkan sumber daya, mengestimasi nilai
Untuk menerapkan pendekatan tersebut dibangunlah sebuah algoritma yang mereka sebut sebagai Adaptive Workload Load Balancing (AWLB).
Tahapan algoritma tersebut jika dinarasikan adalah sebagai berikut.
- Melakukan benchmark terhadap himpunan sumber daya yang dinotasikan sebagai
. Sumber daya di sini terdiri dari kinerja komputasi prosesor, data tampung memori serta lebar pita komunikasi
- Mengestimasi nilai yang mungkin untuk parameter aplikasi
. Nilai minimalnya dinotasikan sebagai
, yang berhubungan dengan kondisi di mana tidak terjadi komunikasi antar proses parallel. Sedangkan batas atasnya dihitung berdasarkan pertimbangan bahwa komputasi yang dilakukan secara parallel akan dieksekusi lebih cepat dibandingkan secara sekuensial. Jika sumber daya homogen, hal ini dapat diekspresikan sebagai
Analoginya, untuk sumber daya yang heterogen batas atasnya dinotasikan sebagai
- Selanjutnya, pada daerah antara
, pencarian dilakukan terhadap nilai
yang optimal dalam meminimalkan waktu eksekusi aplikasi. Aturannya, untuk setiap nilai
- Untuk kasus sumber daya yang dinamis, di mana kinerja dipengaruhi oleh faktor lain (yang umumnya karena pengaruh lingkungan grid), estimasi ulang secara periodik untuk nilai
- Jika aplikasi secara dinamis berubah, misalnya disebabkan karena adaptive mesh, mengganti antarmuka atau kombinasi proses fisis yang dimodelkan pada tahapan simulasi yang berbeda, maka nilai
.

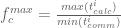
,
.
.
Estimasi ulang secara periodik untuk dua tahap terakhir algoritma AWLB, dapat dilakukan untuk simulasi iteratif, time-stepping, atau kejadian diskrit. Setelah iterasi dilakukan, karakteristik sumber daya akan secara otomatis diperbarui. Untuk kasus di mana kinerja aplikasi turun secara signifikan tahapan simulasi selanjutnya dilakukan dengan distribusi beban yang diadaptasi. Untuk jenis aplikasi lain, menyeimbangkan kembali dapat dilakukan melalui check pointing, yang merupakan kemampuan yang diperlukan untuk komputasi fault tolerance yang efisien pada lingkungan griid. Lagi-lagi, di sinipun saya belum dapat mencapai pemahaman yang baik.
Untuk algoritma AWLB, nilai
Pendekatan dalam perhitungan beban kerja telah dijelaskan oleh penelitian sebelum paper ini seperti dapat diperoleh di alamat ini dan ini. Akan tetapi, berbeda dengan pendekatan yang telah dilakukan tersebut, penulis melakukannya dengan mempertimbangkan faktor berat secara dinamis.
Untuk memahaminya, penulis memberikan asumsi berikut ini. Untuk prosesor ke-i, nilai 
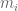
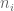

Selanjutnya, untuk merefleksikan kapasitas prosesor, faktor berat 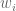


Lebih lanjut, faktor berat didefinisikan dengan mempertimbangkan berbagai faktor terkait sumber daya. Didefinisikan nilai 

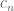
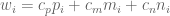

Faktor berat mencerminkan kapasitas sumber daya berdasarkan pengaruh sumber daya